The Harness Is the Moat: Inside the Architecture Powering Autonomous Agents
Part 1 of 5 | Series: What We Learned from the Claude Code Leak
Everyone talks about the model. Which one is smarter. Which benchmark it topped. Which lab is ahead this week. Is Mythos going to change everything?
The Claude Code source leak that happened a few weeks ago tells a very interesting story. The actual API call to Claude, the part that talks to the model, is about 200 lines of code. Everything else, more than 500,000 lines, is the harness around it.
That is why I am starting this series here. The leak matters because it exposed a real, and very successful, production agent stack in enough detail to study how the whole system is put together, not just how the model is called. I want to break that into five parts: harness, memory, control, competitive architecture, and then the strategic consequences once the code is out in the open.
The harness is where the production experience lives. And what Anthropic built is far more complex than most people guessed from the outside. If you are trying to make agents useful inside a real engineering organization, this is the layer that determines whether they stay as demos or become actual execution partners to the engineering teams.
I have seen the same thing in my own stack. My personal assistant agent, my ghostwriter agent, and my execution agent only started becoming reliably useful once the surrounding system got more explicit: startup sync, memory files, voice rules, tool routing, and clear role boundaries. Same underlying model quality, very different outcome once the harness got better.
What the Harness Does#
When you type a message into Claude Code, the model sees only a small fraction of what is happening. Before your message reaches the API, the harness has already:
- Assembled a system prompt from 15 composable sections, split at a precise boundary for caching
- Snapshotted relevant files into an LRU cache (100 files, 25MB) for undo operations
- Checked whether this is an internal Anthropic build or an external one, and adjusted instructions accordingly
- Prefetched memory from
CLAUDE.mdfiles while the previous response was still streaming
The response loop is an async generator. Every event, text chunks, tool calls, progress updates, errors, compaction boundaries, flows through one yield-based stream. The CLI, the SDK, and the IDE bridge consume the same stream. They just render it differently.
This is not complexity for its own sake. Every layer was added because something broke in production at some point as they built Claude Code.
That also matches my own experience. Even small failures that look superficial from the outside usually turn out to be harness problems. I recently had to debug why Telegram slash commands were behaving inconsistently across my agent setup. The issue was not intelligence. It was stale scoped command overrides, config drift, and product-surface behavior. That is exactly the kind of work a real agent system accumulates.
Here is the simplest way to visualize it:
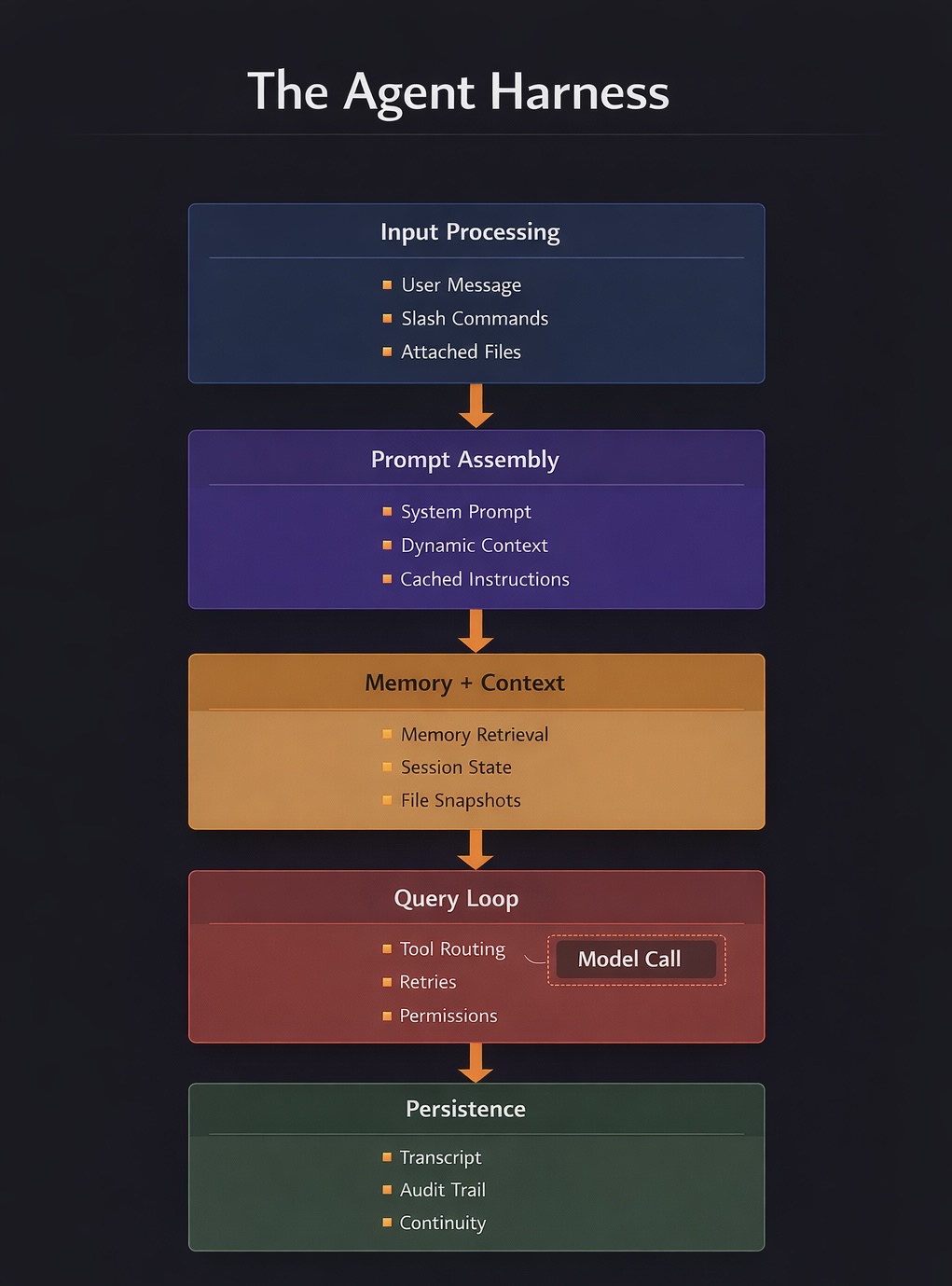
That is the core point. The model is one box in the middle. The product is everything around it.
The Unreleased Features Are the Real Signal#
The most significant finding in the leak is not how Claude Code works today. It is 44 feature flags covering capabilities that are fully built, compiled, and sitting behind flags that evaluate to false in the public build.
These are not roadmap ideas. They are shipped code that has not been turned on yet.
Kairos: the always-on agent. A persistent background daemon that continues operating even after the terminal is closed. Every few seconds it receives a heartbeat: “anything worth doing right now?” It evaluates what is happening and decides: act, or stay quiet. When it acts, it has tools regular Claude Code does not. Push notifications to reach you when the terminal is closed. File delivery for things it created without being asked. Pull request subscriptions to watch GitHub and react to code changes on its own.
This is not a session-based assistant that waits for you to show up. This is an agent with initiative. It has a job, and it keeps working. This is exactly what I am pushing for at Attentive, as we improve our development environment we must aim to support fully autonomous agents that can operate 24 by 7 in partnership and under the direction of engineers.
Coordinator mode. One Claude orchestrating multiple worker Claudes, each with a restricted toolset. The leaked code supports cron scheduling for agents, GitHub webhooks, and external callback support. The architecture assumes that complex work gets broken into parallel sub-tasks, each handled by a specialized agent. Not a single assistant, but using the concept of a team.
Voice mode. A full voice command entrypoint, built and gated. This has never been publicly mentioned. I like this a lot, typing is not my strongest skill and I have been using Wispr Flow on all my devices.
Browser control via Playwright. Not web_fetch. Real browser automation, built into the harness. I have been testing several browser options. I am sticking for now with Vercel’s Agent-Browser.
Agents that sleep and self-resume. Sessions can be paused and resumed without user prompts. This is massive. Being able to resume a session after I lost my focus while multitasking is a killer feature.
The Prompt Cache Architecture#
One engineering decision in the source that deserves attention: the system prompt is split at a marker called __SYSTEM_PROMPT_DYNAMIC_BOUNDARY__.
Everything above the marker is static: behavioral instructions, coding style rules, safety guidelines. Everything below is per-session: the user’s CLAUDE.md files, MCP server instructions, environment context.
The static half gets cached globally. The source mentions Blake2b prefix hash variants, meaning they hash the cacheable prefix to maximize cache hits across users. About 3,000 tokens of instructions are cached and reused globally. Per-session context is injected fresh after the boundary.
This is how you pay for a large, expensive system prompt without paying for it on every single turn. The boundary is not a formatting choice. It is a cost architecture decision.
Anything tagged DANGEROUS_uncachedSystemPromptSection in the code is explicitly marked as cache-breaking, so ANTHROPIC engineers know the cost implication before they touch it.
A/B Testing at the Prompt Level#
Throughout the source, @[MODEL LAUNCH] annotations track prompt wording experiments across model releases. The comments reference things like “capy v8 thoroughness counterweight” with a PR number attached.
Anthropic is iterating on the system prompt the way an ad network iterates on copy. Not just what the model knows. How it behaves. What it emphasizes. How it handles ambiguity. These are product decisions, tested experimentally, tracked across model launches.
This is a meaningful shift in how to think about AI development. The model is one variable. The system prompt is another. Anthropic is treating both with the same experimental rigor.
That is very close to how I think engineering leaders need to approach this transition. Becoming Agentic-First is not about dropping a stronger model into the same old workflow and hoping for a miracle. It is about redesigning the execution system around how agents actually behave under load, ambiguity, and incomplete context.
The Bottom Line for Builders#
The Claude Code source is a rare case of a production agent system at scale being visible in full. We also have open source versions growing fast like LangChain and AutoGen. Most teams building agents today are operating without a reference hardened architecture for what works at this level.
A few things worth taking from it:
The model is almost interchangeable, super easy to switch. The harness is not. If you are evaluating which model to use, you are asking the right question second. The first question is whether your harness can handle a 10-hour session, a context overflow, a permission denial mid-task, a multi-agent coordination handoff.
Features you have not released are still cost centers. The 44 unshipped features in the Claude Code source are compiled into every build. They are disabled, but they are there. Shipping discipline matters.
The session is not the unit of work. Kairos treats the agent’s work as continuous, not session-bounded. If you are building agents and your mental model is still request-response, you are building for yesterday.
For engineering leaders, that is the strategic shift hiding in this leak. The future is not a better autocomplete. It is a new execution layer for the organization.
Sources: Claw CodeHaseeb Qureshi, Inside the Claude Code source · The AI Corner, Claude Code Source Code Leaked: What’s Inside · The Register, Anthropic accidentally exposes Claude Code source code · Engineer’s Codex, Diving into Claude Code’s Source Code Leak · LangChain · AutoGen · OpenAI Swarm · OpenClaw ecosystem: OpenClaw · pi-mono